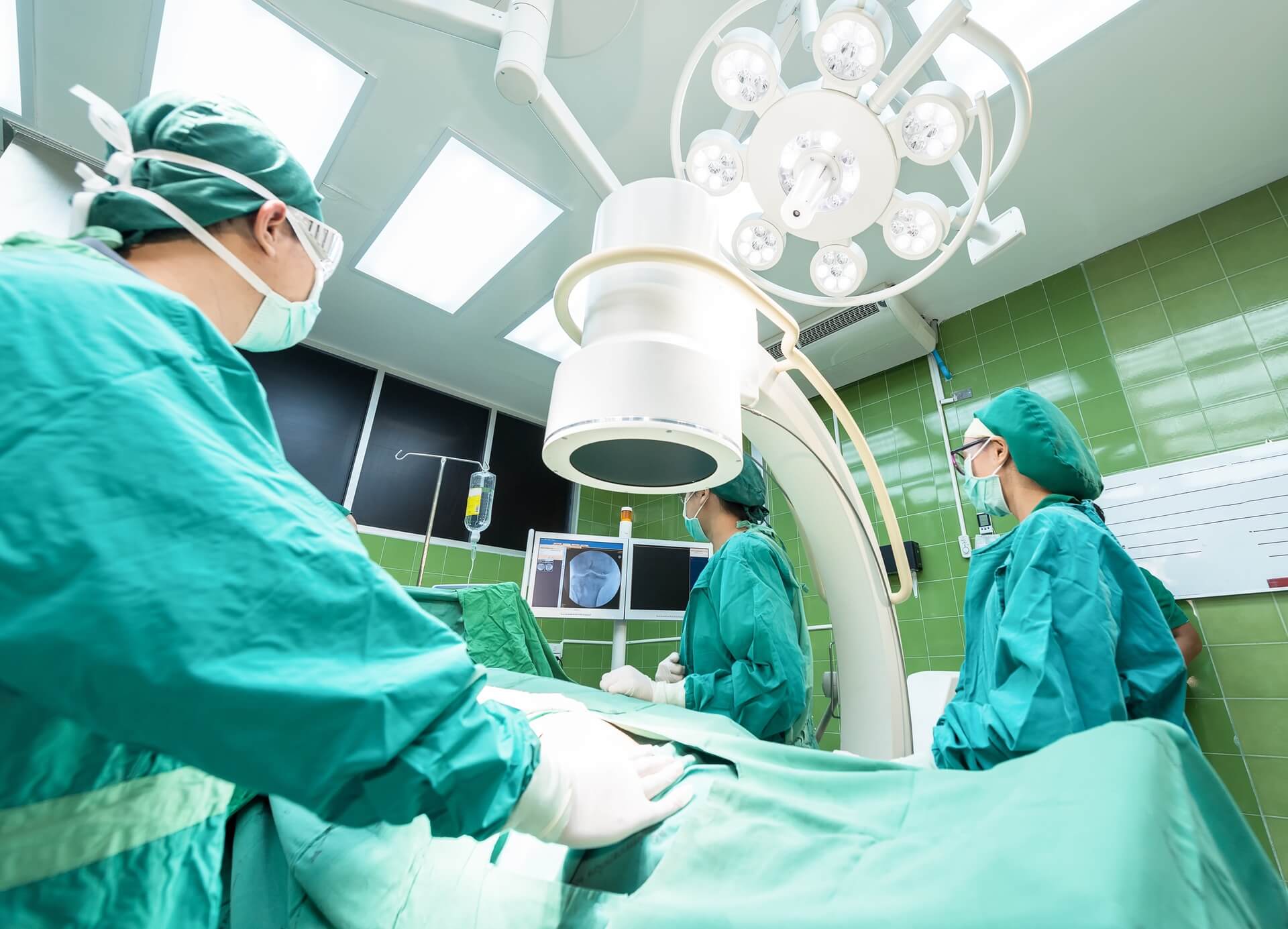
With expanding global clinical trials and stricter regulatory requirements, life sciences companies face growing pressure to translate faster without losing accuracy. AI-powered machine translation (M...
Every patient deserves to be understood, no matter their language or communication needs. Empowering your healthcare organization to better connect with patients who have language needs, accessibility...
Machine translation (MT) offers promising benefits for organizations to speed up time to market, translate larger volumes, and maintain content consistency. It’s impossible to ignore the potential rew...
In every annual enrollment period, health plans need to ensure they meet compliance standards, tight deadlines, and budgetary requirements. This year, with updates to Section 1557 of the Affordable Ca...
The quality and security of your translation and interpretation services can make or break your brand’s reputation and impact your goals. So, a key question for buyers when choosing a language service...
User experience is a huge differentiator in a commercial world crowded with options: Succeeding in today’s global marketplace is about much more than an outstanding product or amazing customer service...
Studies reveal that more than 25 million Americans require language assistance for daily activities. With the help of over-the-phone interpretation (OPI), you can connect your multilingual customers ...
With a focus on advancing health equity and reducing disparities in health care access, the Department of Health and Human Services (HHS) published a final rule in May 2024 to revise Section 1557 of t...
Taking a marketing campaign global is a large investment in terms of time, cost, and effort. The last thing anyone wants is for that launch to flop because of a cultural oversight, but it happens more...
In a world where almost 68 million people in the U.S. speak a language other than English at home, the real challenge isn't deciding if language access services are necessary but figuring out which se...
Is your localization budget working as hard as it could be? Optimizing your localization budget demands more than just careful planning; it requires a strategic approach tailored to your brand's uniqu...
The need for clear, instant communication across languages is exploding in healthcare, education, courtrooms, and more. Compliance with relevant regulations is a key driver of this demand, but it's no...
AI-powered neural machine translation (NMT) has the potential to unite us across miles and languages. But there’s a dark side: it also has the potential to unwittingly reinforce societal biases by pro...
In today’s online and connected world, more companies than ever rely on global teams. This business model offers several advantages, including the ability to recruit top talent worldwide, gain local e...
According to the US Census, approximately 68 million Americans speak a language other than English at home. Many of these people need interpreting services to communicate effectively in English and av...
As we step into 2024, healthcare organizations are embracing a pivotal role as champions of equity and accessibility. In the current regulatory environment, inclusive care and equal access to critical...
With over 500 million Spanish speakers worldwide, localizing for the Spanish-speaking market unlocks a world of opportunity. But if you think all 25 Spanish-speaking markets are the same, think again....
Is your company getting the maximum value for the money you spend on translation and interpretation costs? Developing a strong language access program is the key to supporting a multilingual, diverse ...
Global businesses had to work hard to keep up with all the changes in 2023. Fueled by ChatGPT and its generative AI siblings, demand for content continued to skyrocket, and demand for translation, int...
Currently, 71% of countries have data privacy laws, and those laws are becoming increasingly complex and mature as regulatory bodies and government agencies increase their understanding of the value a...
Are you settling for a “good enough” interpretation provider when exceptional service is within reach? The idea of switching interpretation vendors can feel like more trouble than it’s worth if your c...
From faster turnaround times to increased content, the benefits of AI translation are real and compelling. Google Translate processes at least 146 billion words a day. According to Nimdzi Insights, Ne...
Machine Translation (MT) and generative Artificial Intelligence (AI) are changing the multilingual content production game, helping organizations connect with more customers from different linguistic ...
The focus on health equity continues to be a pivotal force in the healthcare industry's evolution. With 2024 on the horizon, health systems and health plans are set to intensify their efforts to addre...
Free machine translation (MT) tools such as Google Translate are alluring for businesses that want to optimize their translation budget or speed up their translation processes. What could be cheaper t...
In today's international marketplace, global branding is a powerful tool for businesses aiming to connect with multicultural, multilingual audiences. Brands that resonate with local audiences thrive, ...
Whether it’s through websites, apps, patient portals, SMS, or chat, healthcare consumers are demanding the same easy and user-friendly digital experiences they’ve grown accustomed to from retail, bank...
Artificial Intelligence (AI) is everywhere you look, transforming the way we communicate and do business. Generative AI and large language models (LLMs) such as ChatGPT are grabbing headlines for thei...
In this day and age, our comfort with and desire for remote communication is stronger than ever before, creating new challenges and opportunities. One relevant example is from healthcare: the telemedi...
Since its inception, the impact of OpenAI’s ChatGPT has been huge. This unique technology continues to grow and is not going anywhere. ChatGPT consistently dominates the news cycle; every week there’s...
As businesses expand into new markets, they’re engaging with more multicultural consumers than ever before. According to Collage Group, these consumers are more likely to support brands that are relev...
Creating culturally relevant experiences is essential for businesses that are trying to engage with multicultural audiences. In a recent blog post, we described how cultural irrelevance can hurt your ...
Multicultural consumers are now the fastest-growing group of consumers in the United States and currently represent 42% of the U.S. population. Also, non-U.S. markets represent 84% of the world’s purc...
Our team at ULG has developed a seamless and easily deployable language translation connector API between our OctaveTMS platform and the Adobe Experience Manager (AEM) Cloud. OctaveTMS offers an end-t...
Streamline Localization + Translation Projects Using ULG's Integration with Veeva Vault PromoMats United Language Group (ULG) is an official Veeva Technology partner. Through this partnership, ULG has...
In today's globalized world, effective communication across language barriers has never been more important. Translation can help businesses expand into new markets and communicate more effectively wi...
The U.S. population is becoming increasingly diverse. According to the Collage Group, between 2013 and 2019, the U.S. multicultural population accounts for more than 100% of the country’s growth and m...
Is your organization ready for the upcoming regulatory changes affecting medical devices and clinical trials in the European Union (EU) and the United States (U.S.)? Both the EU and the U.S. have rece...
As we reach the end of the public health emergency in the United States, healthcare professionals will revert to addressing healthcare issues such as non-communicable diseases (NCDs). At-home diagnost...
State and local governments are navigating an era of increasing diversity and demand for language access from both constituents and the federal government. According to the U.S. Census Bureau, over 25...
In the United States, 67.8 million people speak a language other than English, and for healthcare organizations, ensuring language access and health equity are critical for improving access to care an...
An optimized, proactive language access plan (LAP) provides a competitive advantage in today’s multicultural environment by helping you reach people where they are. The U.S. population is growing more...
What is localization? Localization is the use of translation with a cultural lens to create connection. Many use the terms localization and translation synonymously. However, while the two words are c...
Did you know more than 350 languages are spoken in the U.S. and nearly a quarter of the American population primarily speaks a language other than English at home? If you want your multilingual outbou...
As healthcare leaders continue to cope with rising costs and staffing shortages, they’re looking to do more with less. Yet cutting corners on translation and interpretation programs isn’t an option wh...
Machine translation tools are rapidly evolving, from the first translation engine built by Petr Troyanskii in 1930 to today's application of neural networks, where the artificial intelligence (AI) bui...
As healthcare organizations continue to battle negative operating margins and rising healthcare costs, efforts to engage and grow patients and members will be critical, particularly among populations ...
Globalization and the continuing digitization of business require high-quality, culturally appropriate translation for your business’s international expansion, but language is only one piece of implem...
As legal writer David Mellinkoff once observed, “The law is a profession of words.” In cross-border litigation, words must be translated and have the same intended impact. Mistakes during the process ...
Displaced peoples were once a far-away issue for many of us—someone else’s concern. But now, displaced peoples and refugees from global hot spots arrive daily at cities and towns across the United Sta...
Your language interpretation needs will hinge primarily on the setting and your participants. In general, one-on-one conversations like medical appointments usually require consecutive interpretation;...
With global disruptions in supply chains and production and general economic uncertainty, growing out and not up is a very attractive option for businesses. Offering an existing product or service to ...
A recent analysis by Deloitte found health inequities currently cost the US healthcare industry $312 billion a year, which could balloon to $1 trillion by 2040 if left unaddressed. Key industry stakeh...
The manufacturing industry is facing a serious labor shortage that will likely worsen. But, recruiting and retaining talent from diverse populations can fill available positions and give manufacturers...
Whether you’re expanding your reach to international markets or meeting people where they’re at domestically, the importance of making sure your message is translated properly cannot be overstated. Be...
Despite the progress made over the preceding decades, inequalities persist in many areas of American life, including healthcare. Disparities in both healthcare access and in outcomes like mortality, l...
Diverse pools of participants in clinical trials are not only important for producing the best set of data, but they also help advance health equity. To reach both goals, you need multicultural commun...
Every year, top golf players from around the world gather to compete in the United States Golf Association’s (USGA) US Women’s Open tournament. Many of these players don’t speak English and require th...
For financial institutions looking to expand their markets through multilingual translation, the stakes are high. As your brand breaks international boundaries, you’ll need to strategize how to best c...
Companies aren’t just building up anymore; they’re building out. There’s never been a better time to expand your business reach by tapping into the global market, and putting money toward language tra...
Call centers often get a bad rap for long wait times, muffled audio, and scripted responses. Customers are often on edge, expecting the worst even before a representative picks up the phone. And more ...
Redetermination after the Public Health Emergency In response to the global pandemic, the United States declared a public health emergency, which allowed individuals and families to remain enrolled in...
In April 2022, the U.S Food and Drug Administration (FDA) released guidance requiring sponsors to create diversity plans to improve enrollment of underrepresented populations in clinical trials. Altho...
The National Committee for Quality Assurance (NCQA) is dedicated to improving the quality of healthcare in the United States. But studies show that the caliber of healthcare individuals receive varies...
How can life sciences companies ensure that they are providing accurate, efficient, reputable translations for the communities they support? The key is to engage a language solutions partner with the ...
When it comes to serving the needs of multilingual customers, many companies settle for transactional translation and interpretation services. What if there was a better way that could help you expand...
Ask any medical professional, and they’ll say their number one goal is to provide quality patient care and positive health outcomes. But there’s more to meeting the needs of patients than writing pres...
How can teams implement language solutions without going over budget? What’s considered “quality” translation and interpretation to begin with? And what’s the long-term return on investment? These are...
Times are changing—and changing fast—in the world of digital technology. Businesses are trading outdated legacy processes for innovative digital transformation technology as their companies grow. Acco...
Have you evaluated your process for translating member grievances and appeals? Even the most conscientious Managed Care Organizations (MCOs) have disputes with patients and their providers. These can ...
This article was originally published in January 2021 and has been updated. Patients from linguistically and culturally diverse backgrounds experience health disparities and adverse health outcomes co...
As of 2022, more than 25 million U.S. residents spoke a language other than English at home, according to the US Census Bureau. Utility companies provide essential services, and it’s vital to ensure t...
Did you know that one in five people in the U.S. speaks a language other than English at home? Imagine them navigating a life where every conversation, every piece of information, feels just out of re...
At long last, the European Union (EU) Clinical Trials Information System (CTIS) is ready for action. That means that on January 31, 2022, EU Regulation 536 goes into effect. Although there is a one-ye...
Language should never be a barrier to receiving information, support or services in legal, financial, medical, business, or non-profit settings. Every customer deserves gold-standard support in the la...
Healthcare providers, take note: effective January 1, 2022, your office must comply with the No Surprises Act. That means it’s your responsibility to make sure that your patients know if they will be ...
From routine checkups to medical emergencies, patients count on hospitals to provide excellent treatment. In order to ensure the best quality care, medical professionals must be able to communicate wi...
With October being National Breast Cancer Awareness month, it is important to recognize the importance of preventative care in reducing readmissions hospitalizations. Further, with the context of toda...
This article was originally published in June 2017 and has been updated. Since it launched in 2008, Spotify has become a leader in the music streaming scene. Over 50 million paid subscribers use the s...
This article was originally published in April 2017 and has been updated. Communication across cultures can be challenging. But in an age of globalization, effective multicultural communication is vit...
It is widely known that healthcare and health insurance are deeply complex and challenging to navigate in the United States. In fact, a 2020 KFF survey found half of consumers who looked for coverage ...
This article was originally published in August 2017 and has been updated. When the now-defunct Braniff Airlines released an ad targeting its Spanish speaking consumers in 1987, it likely couldn’t hav...
A complex health system can’t survive without care coordination. As the world continues to globalize, care coordination models have had to adjust in order to provide access to sufficient healthcare fo...
Brazil's economy is set to grow by 1.7% in 2024, backed by a massive consumer base of over 214 million people. For brands looking to tap into this potential, success hinges on more than just speaking ...
Within the healthcare industry, machine translation (MT) has rapidly come into focus as a solution for managing turnaround time and efficiency within the translation process. However, as organizations...
Solving HRA Completion Rate Challenges with Bilingual Care Liaisons and Bilingual Resources for LEP Outreach One central objective that many health insurers face is increasing Health Risk Assessment (...
Did you know that August is National Immunizations Awareness Month? With flu season right around the corner, now is the perfect time to start thinking about getting your flu shot. Additionally, with t...
This article was originally published in August 2017 and has been updated. Airbnb, the home-sharing service that amassed nearly $47 billion in gross booking value in 2021, is accessible in virtually e...
Healthcare organizations in the United States provide care to a highly diverse patient demographic. Effectively connecting and communicating with these patients is vital to the overall care experience...
This article was originally published in August 2018 and has been updated. In 2018, Facebook received strong criticism for an embarrassing translation mistake triggered by its algorithm. After a 6.9 m...
This article was originally published in October 2020 and has been updated. Terminology management is a critical and key component to ensuring optimal translation quality for all localized content. It...
This article was originally published in November 2016 and has been updated. The world is now more interconnected than ever before. The ease of travel, the internet in all of its forms and the wide av...
The European Medical Device Regulation (MDR) is an extremely daunting set of rules for medical devices within the European Union. The MDR comprises more than 100 articles, making it virtually impossib...
Although the global pandemic is not yet behind us, immense progress has been made in recent months. This would not have been possible without the thousands of clinical trials that took place. With the...
Healthcare is complex. It’s fragmented, can be expensive, and it has long suffered from a lack of coordination. In fact, costs for patients with uncoordinated care are 75% higher than for matched pati...
Although the COVID-19 pandemic will be remembered as a global catastrophe, it also gave rise to worldwide cooperation in order to solve the biggest medical crisis in a century. While the world is not ...
At United Language Group, our experience and commitment to quality have helped us understand our pivotal role in creating true end-to-end partnerships. Most language service providers (LSPs) understan...
Earlier this month, United Language Group (ULG) partnered with LocWorld, Next Level Globalization (NLG), and Boston Scientific to discuss the power of partnership. Speakers Eileen Kerry and Tommy Davi...
Communication is essential to many aspects of everyday life, including personal interactions as well as accessing medical treatment and legal assistance. To learn how to more effectively communicate w...
Even before COVID-19 upended life in every country on the planet, numerous problems existed both globally and locally that international non-governmental organizations (INGOs) are uniquely equipped to...
Effective communication is a vital part of many aspects of modern life. When a patient's health and well-being—and maybe even survival—is on the line, effective communication can be the key to a succe...
Back in 2016, a survey found that just 4% of Americans were able to correctly define all four terms that determined how much they would have to pay for medical services and drugs under their health in...
As the impact of the pandemic is still very much affecting everybody throughout the globe, it has generated profound disruption across the digital health sector. Although COVID-19 has created change i...
As states like Alaska, Mississippi, and Arizona begin opening up appointments for all individuals 16 and older, it seems like “normal” may return sometime in the near future. Yet, for as many people w...
Innovation is the ability to see change through an opportunity. It's the true driving force that sits behind the medical device industry, and it's what saves more and more lives each and every year. M...
Electronic Clinical Outcome Assessment, more commonly known as ECOA, revolves around the procedure of capturing data electronically in clinical trials, as opposed to on paper. Many state that eCOA is ...
In today's world, consumers have a constant expectation to receive things instantly. Whether this is through Prime on Amazon, or free next-day delivery from the billion stores on the web - digital tec...
Throughout the numerous lockdowns that the COVID-19 crisis induced upon us all, remote personal interaction became the new normal. It's what reduced potential exposure for everyone around the world, b...
Medical devices are a vital healthcare innovation. They exist to monitor, replace, or modify anatomy or physiological processes, and improve patient outcomes throughout the means. However, if not adeq...
In the third and final webinar of the series with Ronald Boumans, senior consultant for regulatory affairs at Emergo by UL we learned on the importance of Summary of Safety and Clinical Performance (S...
If you are anything like us, you’ve experienced steady changes with the continuously evolving MDR requirements. In 2020, the new European Medical Device Regulation (MDR) was rolled out. These guidelin...
European Medical Device Regulation (MDR) is continuously evolving, making it difficult to keep up with all of its requirements. It is important to understand these guidelines to ensure that your medic...
It has now been a year since the European Union’s new Medical Device Regulation (MDR) enforcement. It may seem like a long time ago, but there is still work to be done and regulations to understand so...
We are repeatedly told that communication is key, yet many businesses overlook a common communication barrier: language. Language barriers are challenging for everyone involved because they cause misu...
As we round the corner into 2021, the spotlight continues to be on health and healthcare. We know that a healthy diet, physical exercise, and routine check-ups can keep us in tip-top shape, but what i...
The COVID-19 pandemic has shed a spotlight on the systemic inequalities and lack of access to health care for patients and members with Limited English Proficiency (LEP). Across the care continuum you...
Section 1557 of the Affordable Care Act (ACA) prohibits healthcare providers from discriminating against individuals on the basis of race, color, national origin, sex, age, or disability. There are sp...
According to the U.S. Census, the 2018 midterm elections attracted the highest voter turnout in four decades—fifty-three percent of the citizen voting-age population. This represented a higher turnout...
Telehealth has proven to be an incredibly effective response to the stay-at-home orders incited by the COVID-19 pandemic. The telehealth services industry is expected to grow nearly 65% in 2020 as dem...
Happy Data Privacy Day! Do you know how your data is being used, and by whom? The systems we interact with and use every day can compromise sensitive data and leave us vulnerable to phishing schemes a...
Translating legal documents can be a challenging endeavor, especially for translators unfamiliar with the industry. Overcoming legal translation challenges requires a combination of creativity and acc...
Apple. Microsoft. Starbucks. It seems that wherever you go, these brands have a strong presence and a large share of the consumer market. Although most companies start out in one country (or, on a mic...
The countdown to May 2020 is on. With less than a year until the new Medical Device Regulation (MDR) laws are enforced, many manufacturers and healthcare companies are battling a series of implementat...
This article was originally published in July 2019 and has been updated. Artificial Intelligent Machine Translation (AI MT), like ULG's MT technology Octave MT, can unlock tremendous opportunity for g...
This article was originally published in June 2019 and has been updated. Many companies already use instantaneous translation engines—Machine Translation (MT)—for technical documentation and large vol...
Our digital world is changing multilingual communication and the way we localize for global markets. At this year’s LocWorld40 “Go Global, Be Global” conference in Estoril, Portugal we uncovered insig...
Healthcare accessibility is a challenge facing millions, and an issue ULG is dedicated to working to improve. At this year’s “Paving the Way to Healthcare Access” conference sponsored by UMass Memoria...
Since 1947, the International Organization for Standardization (ISO) has been creating quality control standards to ensure the safety of products and services worldwide. With more than 22,000 quality ...
ULG achieved HITRUST CSF certification in 2019 as a means to demonstrate our ongoing commitment to protecting sensitive information and managing data risk. HITRUST is a non-profit authoritative body t...
With regulations such as GDPR and the Right to Be Forgotten frequently in the news, data privacy has become a hot-button issue over the past few years. Medical device companies operating within the Eu...
Smart watches. Smart homes. Smart cars. Smart...pacemakers? The prime example of the Internet of Things (IoT): smart devices. They have permeated the global market in recent years and are steadily gro...
It’s nearly the one-year mark for the Global Data Protection Regulation (GDPR) and we’re starting to see enforcement already. Most notably, of course, is the $57 million fine to Google for violations....
Over the past few years, the EU has enacted a series of new regulations related to healthcare and medical devices. For example, the new In Vitro Diagnostic Regulation (IVDR 2017/746) addresses several...
Almost two years after its initial publication, many medical device companies are still in the process of adapting to the new EU Medical Device Regulation (MDR). Although this regulation was released ...
For content to appeal to a global audience, translating the text is only the first step. Multimedia content is key to appealing to today’s viewers, and localized multimedia content is key to making th...
Today’s announcement that France has fined Google nearly $57 million for GDPR violations. This makes it clear just how serious the European Union is about enforcing the Global Data Protection Regulati...
By Christopher Crowhurst, CTO Last week I became a statistic. One of the half billion – yes, that’s five followed by eight zeros – people who had their information compromised by the Marriot hotel dat...
Consider that 41% of adults and 55% of teens are using voice search every day and voice searches make up 20% of all mobile searches on Google. These numbers are only going to increase as voice recogni...
With the medical industry constantly expanding and sharing knowledge and products worldwide, having a physical file room to house all paperwork and records is no longer a viable option. Medical device...
When the European Union passed the Medical Device Regulation (MDR) back in April 2017, economic operators involved in the importation and distribution of medical devices became subject to new regulato...
As 2018 draws to a close, it’s time to look forward at 2019. The language services industry is always changing, so what will the new year bring? These are our top four translation trends to look for i...
Numbers are numbers, right? A zero is a zero in English the same way it is in Arabic or Mandarin. But what about everything surrounding the numbers in a financial document? What about financial contex...
You’ve probably heard of the project management triangle, a constant balancing act of speed, quality, and cost. Conventional wisdom suggests you can only pick two of these variables at a time. For tra...
When shopping around for a Language Solutions Partner (LSP) to work on their translation project, clients tend to use turnaround time as one of the deciding factors. The faster a product gets to marke...
It’s been six months now since the General Data Protection Regulation, otherwise known as the GDPR, rocked the online business world. How well are consumers and businesses faring under the new legisla...
You’ve probably heard the adage, “A picture is worth a thousand words.” This is especially true when an organization expands its operations or product offerings into new countries and must communicate...
You probably already know about the importance of localizing your website. You’ve heard that people prefer to shop in their native language, but there are also additional benefits of localization that...
The lifecycle of a translation project has many moving parts – translation, proofreading, editing and localization – that need to be accounted for. And even after all these phases are completed and th...
Many organizations struggle to manage the demand for quality digital content and videos in just one language. So, is it worth it to provide content in other languages also? If you have a global audien...
You’ve probably heard the term QA/QC, which stands for “Quality Assurance” and “Quality Control.” Together, they comprise what is known as a “total quality management system” (QMS), a comprehensive se...
A recent Coca-Cola marketing campaign in New Zealand didn’t go as planned for the giant soft-drink manufacturer. The company attempted to combine a popular greeting that English-speaking New Zealander...
You’ve identified a need to expand your company offerings to a new country or revamp your existing materials to better communicate with different audiences around the world. You’ve collaborated with y...
Interpreters play an essential role in helping people who speak different languages communicate in a wide range of scenarios, such as business meetings, emergency medical calls, and legal support. In ...
Marketers know the importance of understanding current trends and being able to separate effective tactics from trendy buzzwords. What about translation and localization? You might be wondering just h...
The bulk of translation projects are conducted on computers and through the Internet. The client must transfer the original document and any supplementary materials to the translator at the start of t...
The International Organization for Standardization (ISO) is the world’s leading quality control organization that sets standards related to manufacturing, product labeling, and safety. Many companies ...
Does your language service partner (LSP) offer a TMS connector along with their translation management system? If you’re not sure, or you have no idea what a TMS connector is, you’ve come to the right...
Until the late nineteenth-century, Japan was characterized as an isolationist nation with a self-contained economy and culture. The twentieth and twenty-first centuries saw Japan’s rapid rise as a maj...
When a document needs to be translated, it’s tempting to plug the words into Google Translate or log onto Upwork to find a freelancer who specializes in the language you need. While these methods migh...
Spurred by globalization, international expansion within organizations, and increased migration patterns, growth in the language solutions industry has been accelerating at a rapid pace. According to ...
When a Language Solutions Partner (LSP) translates a document for a client, they adhere to quality assurance standards by assembling a professional team that includes linguists, subject matter experts...
How much will good translation services cost? It's one of the most common questions we hear from clients. It's also one of the most challenging questions to answer, simply because there are so many va...
In 2011, the American trivia game show Jeopardy! featured a special guest contestant: IBM’s Watson, a supercomputer. Watson was selected to compete against the show’s top winners, Ken Jennings and Bra...
A translation memory (TM) is one of the most effective methods for reducing time and cost when completing a translation project. It is an electronic database that keeps track of certain segments of a ...
It’s that time of year again. Across the United States, children are heading back to school. Naturally, many children have mixed feelings about this. However, English Language Learners (ELL) and their...
According to the International Data Corporation (IDC), 40% of digital transformation initiatives will use Artificial Intelligence (AI) services by 2019 and 75% of enterprise applications will use AI b...
Facebook has over 3 billion users located around the world. With such a diverse global audience, translation is now an essential part of Facebook’s business model. Here are 5 ways Facebook is using tr...
For organizations undergoing an international merger & acquisition or considering one in the future, it is imperative that all parties involved understand the terms and conditions of the deal and ...
According to the Mayo Clinic, "hundreds of thousands of people" are injured by medication errors every year in the United States. Some of those errors are caused by doctors prescribing the wrong medic...
Since 1947, the International Organization for Standardization (ISO) has created thousands of quality control parameters for a variety of industries to ensure that global companies produce the safest ...
Suppose you go to a garage sale, and you find a first edition copy of a well-known book, signed by the author. You want to buy the book as a gift for your best friend, but you don’t know if the signat...
The World Cup kicked off earlier this month. Soccer fans from around the world are gathering in Russia to watch the games in person. Millions more are following along at home. This major international...
Organizations use videos for a variety of purposes, including employee training, product instructions, and marketing. In recent years, video has proven to be a particularly effective means of engageme...
After a two-year transitional period, the day has finally come – today the General Data Protection Regulation (GDPR) goes into effect, forcing companies across the globe to abide by a new set of data ...
Manufacturing is an industry that is constantly changing in terms of the technology used, the industrial and consumer products created, and the countries where the factories are managed. A recent stud...
Last week ULG hosted a webinar on the language-specific requirements of the European Union’s new Medical Device Regulation (MDR). Renowned MDR expert, Ronald Boumans, discussed key language-specific a...
Translation is essential for today’s global businesses. It allows multilingual teams to work together, makes it possible to communicate rules and operating procedures to employees around the world, an...
When prospective clients approach us with a new project, one of the first questions they ask is about the turnaround time. How long is it before the translation project is finished? The short answer: ...
In the language services world, the two concepts that are discussed most frequently are “translation” and “localization.” Although the two have a lot in common and are often used interchangeably, ther...
The European Union’s new Medical Device Regulation (MDR) will begin being enforced in 2020. It seems like a long way off, but it will be here sooner than we think. The regulation, which represents a s...
When sending a communication in a different language, it can be tempting to rely on an online translator like Google Translate that provides instant results. After all, we all love a convenient soluti...
May 11, 2018 On a recent trip to Australia, French Prime Minister Emmanuel Macron committed a rather embarrassing slip of the tongue. “Thank you and your delicious wife for your warm welcome…” Macron ...
May 08, 2018 Today’s global companies face an interesting paradox: Technology enables them to reach new audiences around the globe, but also forces them to overhaul their communication strategies to s...
According to the Center for Disease Control, in the U.S. alone there are 990.8 million physicians’ visits and 267.1 million emergency room visits or hospital outpatient visits in a year. The patients ...
Strong communication is foundational to your relationships with customers. With more than 25 million people in the United States who are limited English proficient (LEP), most companies have at least ...
While HIPAA compliance might complicate your life, the goal of the regulation is really the same as yours: protecting patients. You’re looking out for their physical well-being, while HIPAA is safegua...
This article was originally published in April 2018 and has been updated. If you’re at all familiar with the language translation industry, you’ve heard debate about the pros and cons of machine trans...
It’s a familiar trope that emerges time and time again in science fiction: human invents machine, machine becomes smarter than human, machine replaces human. However, in the language services industry...
This article was originally published in April 2018 and has been updated. How do you know when machine translation is right for a particular job or for your business? While some translation jobs are b...
Since 1977, the Foreign Corrupt Practices Act (FCPA) has been the leading anti-corruption legislation for companies in the U.S. and those that trade on U.S. financial exchanges. The law lays out stric...
From Experian to Facebook, large-scale data breaches have become a regular part of the news cycle. But the need to protect customer data isn't limited to enterprise organizations. Companies of all siz...
What makes quality healthcare? The Hospital Consumer Assessment of Healthcare Providers and Systems, or HCAHPS, looks to answer that very question, and has been used since 2006 to gauge patients’ pers...
Business communication almost always relies and builds upon material that has already been created, unless the company is new. You don’t write a new company description every time you send out a press...
Published on May 11, 2018 In recent years, the European Union has introduced various measures to improve data security and protect citizens’ personal information. To this end, the EU Privacy Shield wa...
How good can Machine Translation (MT) be? Very good, according to Microsoft. Earlier this month, the tech company announced it had created an MT system that reached “human parity” in translating Chine...
Medical professionals are increasingly noting the correlation between patient health and health literacy. The more people are able to comprehend and understand about their healthcare, the more effecti...
With the GDPR deadline rapidly approaching, organizations are taking the final steps toward ensuring compliance for their data security systems. In Articles 33 and 34, the GDPR outlines the specific p...
Post-editing is a critical part of the process when you use Machine Translation (MT). In exchange for the speed, efficiency and friendly price tag of MT, you’ll have to spend some time reviewing and i...
Scientific and medical advances are often dependent on the results of research involving human subjects. This research requires significant ethical and safety considerations, and clinical trials invol...
On May 5, 2017, the European Commission released the new Europe (EU) Medical Device Regulations (MDR) in an effort to create a more unified and transparent system for medical devices. The MDR will bec...
May 11, 2018 To understand HITRUST, it’s best to temporarily forget everything you know about HIPAA regulations, compliance and audits. Why? Chances are you view HIPAA as a challenge or an obstacle, w...
Did you know that February 21 was International Mother Language Day? UNESCO (United Nations Educational, Scientific and Cultural Organization) began observing International Mother Language Day in 2000...
May 11, 2018 If your company is located in Europe or does any amount of business there, you’re probably well aware of all the upcoming regulatory changes. From investments to data protection to medica...
The European Union’s General Data Protection Regulation (GDPR) is slated to be enforced on May 25, 2018. With just over three months left before the legislation goes into effect, organizations should ...
May 11, 2018 With just a few months left until the European Union’s General Data Protection Regulation (GDPR) takes effect, consumers should feel good about stricter rules for the handling and storage...
It's the middle of February already, and the new year is no longer new. But not according to the Chinese lunar calendar. In fact, Chinese New Year celebrations start this week! With that in mind, here...
May 11, 2018 As companies expand their global reach, they encounter greater opportunities to interact with consumers from different countries, learn more about their clients’ interests, and adapt thei...
The Foreign Corrupt Practices Act (FCPA) enacted in 1977 to make it unlawful to pay foreign governments to secure or retain business, has been getting a lot of attention since the U.S. Department of J...
With legislation like the GDPR coming into effect in the E.U. and multiple news stories of data breaches taking place in the U.S., the need for companies to protect personal data is more important tha...
This article was originally published in January 2018 and has been updated. Machine translation (MT) gets a lot of media hype: some deserved, some not. Read on to learn the truth behind three of the m...
The New Year brings new resolutions, goals and strides toward self-improvement. In 2018, it also welcomed a new regulation into the financial world. The Packaged Retail and Insurance-Based Investment ...
The climate crisis continues to intensify natural disasters causing unprecedented destruction across the globe. From hurricanes and floods to droughts and wildfires, natural disasters in the U.S. alon...
In 2017, mobile apps were downloaded by users more than 197 billion times. Over the last few years, apps and mobile marketing have represented a large percentage of the marketing mix, with companies u...
With stories of workplace harassment dominating the news, one thing is clear: businesses of all sizes must take action to prevent being caught up in costly scandals of their own. If you think this onl...
Government agencies – specializing in anything from education to international diplomacy – often encounter many of the world’s 7,000 languages, making access to translation and interpreting services i...
Chances are your company stores far more data in the cloud than just a few years ago. This likely includes sensitive information that you need to protect, including financial data, business strategies...
As a growing number of businesses expand their market reach to compete in the global economy, the need for legal transactions that span multiple languages, cultures and legal systems has become greate...
With the resurgence of dangerous diseases such as whooping cough, malaria, and cholera, the need for clinical trials spanning the globe is stronger than ever. Diseases affect people differently depend...
The terms “hack” and “data breach” elicit a great amount of fear in today’s ever-connected world. Hackers are a tremendous threat to any large corporation, something that major companies like Equifax ...
Working with quality translators is important, but how do you measure return on investment (ROI)? It sounds simple, but it's often more complicated than it seems. There's not one set of metrics that w...
Defined as people born between the late 1980s and early 2000s, millennials are one of the largest and most influential consumer bases, with an estimated $200 billion to spend each year in the U.S. alo...
In 2017, Language Service Providers (LSPs) are offering clients a plethora of Machine Translation (MT) options. In fact, today anyone with access to a computer can translate fairly simple sentences fr...
The final versions of the European Union’s new Medical Device Regulation (MDR) and In Vitro Diagnostic Regulation (IVDR) were published in May of 2017, representing major changes to the EU’s medical d...
The misuse of prescribed medication can lead to serious health problems. Policy makers in the United States are working to implement legislation that will help put an end to the ongoing opioid crisis,...
As the world’s fourth largest economy and the largest country in the European Union, Germany has become one of the most sought-after destinations for global marketers. The country’s 80 million citizen...
In 2009, EU Machinery Directive 2006/42/EC became mandatory for manufacturing companies selling or distributing products in the European Union. While it’s by no means new, Directive 2006/42/EC is a po...
Thanks to recent technological advances, the translation industry has undergone extensive change. The old-fashioned method of individually translating words (metaphrasing) that make up a sentence and ...
Kathrin Bussmann is busy. The Worldly Marketer Podcast host and founder of global marketing agency Verbaccino juggles both projects by herself, and has been doing so for the past three years. She prod...
Executives are busy. It's difficult for them to devote time to new training. And taking an eLearning course may require them to use new technology, adding to the perception that it will be especially ...
Both federal and local laws require school districts to provide translation help for English Language Learners (ELLs) and their families. Schools often struggle with ELL compliance. But they must stil...
Common Sense Advisory (CSA Research) has made a name for itself as one of the big players in language industry news and research. The Massachusetts-based company produces research and blogs relating t...
Everybody likes to save a buck. In the corporate world, turnaround time and cost efficiency are a procurement manager’s best friend. Given the demanding pace of global business, everyone is looking to...
You’ve purchased a new product online, and you can’t wait to get your hands on it. Once it arrives in the mail, you use your car key as a de facto box cutter, remove the packaging and get rid of the p...
“Everything becomes a little different as soon as it is spoken out loud.” That’s according to author Herman Hesse, and it’s true. Speech introduces different phonetic pronunciations, does away with th...
“What do you do at work?” It’s not uncommon for those in the language industry to answer this question. Assumptions about Language Service Provider (LSP) employees run the gamut, but the most common i...
So, you’ve identified a need for language services. Maybe you’ve got a big interpreting project that needs to be done, or an assignment that requires hundreds of pages of Mandarin to be translated int...
Having trouble learning another language? A glass of beer might help. That’s according to a study published last week in the Journal of Psychopharmacology. It found that those who had consumed alcohol...
Editor’s Note: Claudio Federico is ULG’s Managing Director of OPI Services and has worked in the interpreting industry for several years. Here he details some experiences he’s had in the industry with...
There’s a lot that goes into a successfully localized software application or website. After you’ve translated your source materials, there are steps that need to be taken to ensure your content will ...
The Health Insurance Portability and Accountability Act (HIPAA) was enacted in 1996. It's been the law of the land for 20 years, and even people who don't work in the healthcare industry are aware of ...
Imagine this…. In a typical translation process, the client sends the content to be translated to the translation vendor. Then the translation vendor sends the data to the individual contractor doing ...
Open enrollment planning is more important than ever. With the global pandemic and systematic racism health equity is being considered for every strategy - including OE and Annual Enrollment Period. H...
A visit to the dentist isn’t everyone’s idea of a good time. In fact, dental checkups cause some people so much anxiety, it stops a number of them from obtaining care. A 2012 study found that UK resid...
New research indicates there is yet another reason to learn a second language. A study published in Bilingualism: Language and Cognition suggests children who grew up bilingual have an easier time lea...
Morocco is a prosperous, open country with a low tax rate and a large labor force. A truly global economy, international trade makes up 80% of Morocco’s GDP. Like other highly global economies such as...
On Saturday, Sept. 30, translators from all over the world will have reason to celebrate. The date marks International Translation Day, which gained official recognition from the United Nations in May...
The translation industry is seeing a boom in Machine Translation (MT), both in use and technology. As these MT technology uses and applications evolve, a standardized MT scoring method is desperately ...
Despite its size, the language industry is most likely not well known to those who aren’t directly involved in the field. Niche terms like LSP (Language Service Provider) or “Post Editing,” probably d...
Video Remote Interpreting (VRI) has risen in popularity as the technology becomes more readily available in the courtroom, hospitals and during international conferences. According to a recent reader ...
Here at United Language Group, we often emphasize the importance of language translation and interpreting in the medical field. For us, there’s a clear-cut rationale behind language access in healthca...
The dangers of using free, online Machine Translation (MT) tools recently became a painful reality for Statoil, the Norwegian oil manufacturer. Employees there found that internal memos and correspond...
Japan is the third largest economy in the world and is considered a trend-setter amongst the world’s most powerful countries. Its GDP per capita is eight times greater than China’s, which has the larg...
The past week has been tragic for residents of Houston and the surrounding area as they look for relief in the wake of Hurricane Harvey. Meanwhile, in India, monsoon rainfall has ravaged the country a...
In the translation industry, there are usually unequivocal sentiments surrounding the efficacy of different processes and strategies: Machine Translation is helpful but it’s not perfect; you should al...
In the developing world, access to adequate healthcare, food, water and other necessities is still a problem that has yet to be solved. The World Food Programme reports that one in six children in dev...
There are more than 3.5 billion internet users in the world, and roughly 1.2 billion websites live on the internet. In 1994, there were less than 5,000 websites up and running. When that number reache...
In many ways, the translation process is like a large, complex game of telephone. You have linguists, project managers, clients and designers all trying to effectively communicate with one another to ...
Technical translations might not be thought of as the most glamorous localization projects – IFUs, data sheets, and user manuals aren’t many people’s idea of “exciting.” But they’re important, and no ...
If you’re in the market for translation services, you’ve probably noticed companies like VIA advertising “native-speaking translators.” You may be wondering, “What does “native-speaking” mean, anyway?...
Spoiler alert – the answer is likely yes. What might be more interesting, however, is the “why”. Spanish is a vibrant and growing language that spread through Spanish Colonization to become the world’...
WHAT IS A TRANSLATION GLOSSARY? A translation glossary is an index of specific terminology with approved translations in all target languages that is used by a company and their clients. Glossaries ai...
Digitization has permanently changed many industries over the past decade, and restaurants are no exception. To keep up with technologically savvy consumers, many restaurants have started to offer dig...
Are long translation turnaround times holding your business back? Today's world is interconnected and fast-paced. Time is money, and in so many business situations, waiting weeks or months for transla...
A study shows that companies with localized apps saw 128% more downloads within just the first week of adding more languages. Global consumers want to use apps that are available in their native langu...
Machine Translation (MT) can be a daunting subject with its multiple training approaches and long list of terms. Those new to MT can easily get confused when words like Curated MT, bleu scores, corpus...
With Europe's largest economy (and the third largest worldwide by GDP), Germany offers a lucrative playground for global brands. Yet, entering this market demands more than just translating your conte...
July 17, 2017 Oftentimes, getting quality translations isn’t considered to be top priority for a global project or initiative. Why should you have to pay money to translate your content, when you can ...
With a population of over 130 million and an expansive group of young, working-age citizens, Mexico is quickly becoming a point of interest for global marketers. Despite significant perks, marketers s...
If you’re looking to buy translation services, there’s a lot to consider. You’ll have to look for a Language Services Provider (LSP) that is tech savvy, uses automation to speed up processes and cut e...
If you are trying to expand globally, you should pay close attention to the Chinese market. China has the most Internet users with 731 million. While the opportunities for digital marketing are bigger...
Inevitably, when a new real-time translation earpiece hits the market, media outlets gobble up the news, putting out article after article referring to the new device as the answer to breaking down la...
It may be the middle of summer, but schools and school districts are already gearing up for fall. In all the preparations, are students with Limited English Proficiency (LEP) and their families being ...
With the General Data Protection Regulation (GDPR) less than a year away, any company that does business in the EU will soon need to ensure that they’re following regulations on secure customer inform...
If you’re looking to promote your brand across the globe, creating compelling multilingual materials is just one side of the digital marketing coin. Successful international businesses effectively uti...
The Fourth of July is an American holiday celebrating the Declaration of Independence from the British Empire in 1776 (sorry ULG’s London office). Like more formal holidays like Christmas or Thanksgiv...
Over the years, Latin America has become a prime spot to conduct clinical trials. Countries within the region share several key features that give clinical researchers a lot of reasons to look to thes...
Some may have grown tired of the debate over whether humans will eventually be outdone by machines. But the fact that it’s constantly talked about doesn’t dampen the reality it signifies: the calm bef...
Let’s examine a hypothetical: You’re creating a global branding scheme for a new product. You need to create foreign language content in order for your materials to resonate in local markets. How do y...
A website will make or break a company’s global brand. For a potential client, there’s nothing quite as frustrating as going to a website looking to find information or buy a product, only to get bogg...
Both writing and completing a Request for Proposal (RFP) can be a meticulous and time-consuming process. Regardless of the industry, ensuring you ask all the correct questions to find out as much as y...
Max Schrems nudged himself into the international spotlight in his early twenties. The Austrian law student and privacy activist was not yet 25 when he filed a complaint against Facebook, arguing that...
The translation industry has seen dramatic growth lately, and it’s only expected to get bigger. GALA predicts the market will be worth more than $40 billion by 2020, and at the rate global business is...
What are the best languages for business translation? And how do you know which languages your business should use? To help narrow it down, we’ve put together a list of the 10 most popular languages f...
There are a diverse range of strategies available to people interested in learning another language. There are computer programs, a number of mobile apps as well as more traditional classroom options ...
The Regulation on Medical Devices (MDR) and the Regulation on in-vitro Diagnostic Medical Devices (IVDR) went into effect in May of 2017, effectively replacing decades-old legislation and creating new...
Occasionally, the first thing a translation company representative hears when they are contacted by a new client about possible work is, “Great! We’re going to give you a translation test.” That’s und...
Social media round-up for October 21, 2016 This week on the Common Sense Advisory blog, Arle Lommel asked us all if we could be missing business opportunities because we might be targeting in the wron...
The Icelandic language is disappearing. The culprit? Artificial Intelligence. Well, at least that’s part of the problem. The Associated Press reports that English tourism and foreign labor has also pl...
Website localization has become a heated topic in Illinois government as of late. Recently, some lawmakers in the state had pushed for an amendment to HB 695, also known as the Legislative Information...
Healthcare is understandably one of the most regulated industries in the US today. A long list of laws and regulations ensure that language barriers don’t keep people from accessing healthcare. But st...
The fictionalized robot, Hal, made his debut in 2001: A Space Odyssey nearly 50 years ago. More than four decades later, it doesn’t seem like we’ve reached the level of super intelligence that was por...
The tremendous effects of bilingualism on the brain are well-known. They can improve your problem-solving abilities, shape your world perspective, and can delay diseases like Alzheimer’s. Another impo...
The DOJ recently increased its Foreign Corrupt Practices Act (FCPA) Enforcement unit by more than 50% and the FBI tripled the number of agents focused on overseas bribery. Furthermore, there are curre...
Most people will walk into a popular chain restaurant and already know what’s on the menu. Restaurants stick to what works, usually focusing their menus on insanely popular, yet predictable meals for ...
India continues to grow as a key online market. However, there is one big problem standing in the way—language. Out of India’s population of 1.3 billion, a vast majority don’t speak English, despite t...
May 02, 2017 United Language Group gained new insights into the needs of telehealth clients at this year’s American Telemedicine Association Telehealth 2.0 conference in Orlando, Florida. In particula...
There’s been a lot of talk about healthcare lately. With a new administration in the White House and “Obamacare” tenuously hanging in the balance, the future of the Affordable Care Act (ACA) is uncert...
As with many industries affected by the technology boom, eDiscovery is predicted to grow in economic stature and complexity in 2017, creating both new obstacles and opportunities for legal teams. The ...
April is National Minority Health Month, and this year's theme is "Bridging Health Equity Across Communities." But right now, in too many communities, health outcomes are anything but equitable. Here,...
Recently, the European Union’s (EU) need for Irish interpreters has been thrown into the spotlight, as they struggle to find qualified candidates to fill those job vacancies. Although only spoken by a...
This post was published in April 2017. More and more, law firms are using multilingual eDiscovery tools to sift through foreign language documents in legal cases. Often times, legal teams need to exam...
By Steve Angell and Marco Marino Trade shows, expos and industry conferences are a big investment of your time and resources. Getting a good return on that investment requires some preparation beforeh...
Anyone who’s completed a major translation project knows that it can be a costly, time-consuming process. But those with experience in the language world also know there are ways to streamline workflo...
In Mid-March, United Language Group (ULG) announced its acquisition of Lucy Software, a leading SAP and Machine Translation (MT) provider. The merger is an exciting one for ULG, and a great opportunit...
This article was originally published in April 2018 and has been updated. Machine Translation (MT) and its applications continue to gain traction as one of the hottest topics in the language industry,...
One of the most prevalent mistakes made by designers of international websites is the use of country flags to represent different languages within a site’s language selector. While flags are tempting ...
Domesticated animals were one of the first “technologies” humans employed for survival -taming, training, and breeding different species for different purposes. We domesticated horses to carry us long...
As clinical trials have emerged in the global marketplace, Pharmaceutical Organizations and Contract Research Organizations (CROs) need to be more cognizant of the challenges that can come with transl...
Arabic is one of the five most spoken languages in the world, and it's the fastest-growing language in the US. Whether you're trying to reach people in one of the 26 countries where it's an official l...
Like the NFL, the National Basketball Association (NBA) has a keen interest in expanding the popularity of its sport beyond North America. With rabid fanbases developing around the globe, the NBA has ...
In the world of global marketing, localization is king. Through a well-planned and researched localization process, brands can travel all around the world. While many think of localization as a large-...
A foreign business trip is a daunting undertaking for anyone. The fear of not understanding workflow, customs, business etiquette, and communication styles can present seemingly insurmountable challen...
Spending hours, sometimes days, at a time fine tuning the phonetics, grammar, verb tense and vocabulary of an invented language probably isn’t everyone’s idea of a good time. But for “conlangers,” thi...
Language literacy in the United States may be more important now than ever. With the internet fueling globalization and ecommerce around the world, the 21st century has forced us to acclimate to a wor...
Want to streamline your next translation project? Choosing the right translation provider is important, but that’s only half the equation. The other half is up to you! There’s a lot you can do as a cl...
An ambitious new language learning campaign has dedicated itself to the promotion of bilingualism in the United States in response to a growing need for multilingual speakers. Lead With Languages, a m...
Amazon announced last week it will begin rolling out a Spanish language version of Amazon.com. The addition came just days after the retail giant said it would launch its Amazon Prime services in Mexi...
Today, India will be caught up in the celebration of Holi, a Hindu holiday that takes place on the final full moon in the lunar month of Phalguna, which occurs in February or March. For its participan...
You’re probably familiar, maybe unknowingly, with some form of native advertising. Native ads are the ones found tucked into social media feeds or websites that are meant to blend in with existing con...
Your website is designed perfectly! It’s got appealing colors, intuitive content layout, and quality content. But more than likely, your website is built for a single culture—your own. Will that same ...
Although we still have four months until the new year hits, 2018 will be here before we know it. And in less than 10 months, businesses around the globe will need to be compliant with the European Uni...
In 2005, the Arizona Cardinals and San Francisco 49ers played in Mexico City at Estadio Azteca. Despite what was viewed as subpar play, the game, marketed as “NFL Fútbol Americano,” was a massive succ...
Translated content needs to be tailored to the target audience it’s meant to reach. And validation processes throughout a localization project ensure global materials are not only linguistically corre...
In a global economy built on competition and efficiency, it's imperative that you avoid the pitfalls of legal translation. Misused phrases, misplaced hyphens and poor syntax — mistakes as commonplace ...
In a recent battle of man vs. computer, human translators proved they still outperform Machine Translation (MT) systems notwithstanding great progress in artificial intelligence technology. In a compe...
There are 7 billion people who speak between 6,000 and 7,000 different languages on earth. While a few languages are spoken by hundreds of millions of speakers, such as English or Chinese, most are sp...
This week we scrolled far back into our archives to reach ULG’s very first blog post. This search through our archives got us thinking about what has changed with the “new” Brazilian Portuguese spelli...
United Language Group (ULG) was created in June of 2016, after acquiring KJ International Resources (KJI) and Merrill Brink International, two leading language service providers. The merger has allowe...
Need to view the White House’s website in Spanish? No problem. A global Language Service Provider (LSP) has started a campaign to add Spanish language content to the site. The translation company has ...
Yahoo. eBay. Target. Sony. Home Depot. What do these companies have in common? They are among the many organizations that have been affected by a major data breach, resulting in millions of personal r...
Acronyms and abbreviations are one of the trickiest localization items to handle. While shortening words and phrases can make life easier when writing in your local language, translating acronyms can ...
What do all successful localization projects have in common? Proper planning. One way to start your project off correctly is by defining your expectations with the help of a “localization kit” or chec...
At ULG, we’re often asked “Why do I need to translate my content when everyone speaks English?” So we thought we’d tackle three common misconceptions about the need for translation head-on. Misconcept...
So, you want to learn another language? We can’t blame you. There are so many benefits to becoming bilingual (or trilingual and beyond) that relate to the brain, personal development and business oppo...
A study published last week found that Limited English Proficiency (LEP) Latino patients are less likely to adhere to medication regimens for type 2 diabetes than white and English-speaking Latino pat...
Translation errors can be embarrassing – sometimes extremely so. Coke once learned this the hard way when an advertisement on its vending machine inadvertently said "Hello, Death" in Maori. Lucky for ...
Speaking more than one language is impressive. But being able to professionally interpret for someone who speaks a different language? That’s an even bigger feat. Language interpreters transmit ideas ...
Russia has been getting its fair share of media attention lately. While most of it is political, which we won’t touch with a ten-foot pole, there are some interesting translation news stories coming o...
Earlier this month, we published a blog that focused on the role language plays in scientific research. Specifically, we looked at the results of a study that suggested a lack of scientific, multiling...
Sorting through documents in a legal case is a task in itself. Finding relevant materials for trial can mean sifting through thousands of pages of records in order to find documents that are pertinent...
The proliferation of technology has brought our world closer together ensuring that globalization is here to stay. For businesses, this now means in order to be internationally successful, they have t...
Learning a language is a fun and easy way to exercise your brain. Whether you’re retired, curious, or just want to practice your existing skills, it’s never been an easier endeavor to undertake than i...
In the medical device industry, regulation is a big deal. Proper training for internal operations staff, and consumer and professional end users, needs to be done effectively in order to ensure patien...
Electronic Labeling (e-labeling) has the potential to be hugely beneficial to medical device companies creating Instructions For Use (IFU), labels and packaging information. But at the same time, the ...
While technology continues to advance non-stop like a runaway train, our seemingly unlimited access to information increases every day. And it’s no secret that today’s technological advances have dram...
In 1980 Willie Ramirez was taken to a Florida hospital in a coma. His family members explained to doctors that the 18-year-old was “intoxicado,” in Spanish, meaning poisoned. An interpreter misunderst...
When English speakers learn to read and write, we’re taught words and letters flow from left-to-right. That’s because we’ve learned a language and an alphabet based on Latin languages (e.g. English, F...
A new study suggests using English as the “lingua franca” in the scientific community has severely impeded the transmission of ideas. A paper published last week in the journal PLOS Biology argues tha...
To be successful in the global marketplace, companies need to create marketing material in more than one language. And in order to create an effective globalization campaign, you need a Translation Ma...
Machine Translation (MT) cuts down on cost and turnaround time, thanks to its ability to decipher large amounts of text quickly. The downside to MT is the fact that it doesn’t have the capacity to tra...
Let’s face it, as a society we are addicted to technology. The Internet of Things (IoT) revolution has taken over and there’s no looking back. Considering that 90% of the world’s data was created in t...
India is the second most populous country in the world with 1.2 billion citizens. It also has one of the fastest growing economies in the world with a middle class population that, by some measures, i...
There is a positive relationship between parent engagement and student success. In other words, when families are involved in their children’s learning both at home and at school, their children do be...
It will be a highly competitive year at the 89th Academy Awards across many of the top prizes, including the award for best foreign language film. There are 85 submissions from all around the world, a...
One of the largest countries in terms of both land and population, Brazil also happens to be one of the fastest growing economies in the world. Economic expansion (despite a recent recession), a growi...
A faulty translation can lead to embarrassing, and sometimes dire, consequences. Companies are at risk of suffering severe damage to their reputations when global content is translated incorrectly, an...
Undoubtedly, the digital age has fundamentally changed how people both buy and sell. To counteract these radical shifts, a business’s global marketing strategy has to quickly adapt to these changes. A...
Technology is beginning to keep pace with globalization to help us connect like never before. Whether you’re traveling abroad, living in a multicultural area where your primary language isn’t spoken o...
With 2017 right around the corner, we’ve had a number of health systems and hospitals contact us recently to help them translate their Financial Assistance Program materials by the end of the year. We...
Progress made in the digital age has been remarkable. In the 21st century, it seems the possibilities are endless when it comes to data sharing and the transfer of content; the Internet has broken dow...
This week Google announced that its translation app will add Neural Machine Translation (NMT) to eight of the languages it translates for. Maybe more importantly, it presented findings on “zero shot” ...
With the largest global population speaking the most commonly language in the world, China is one of the most lucrative targets for any business planning a global marketing strategy. This country has ...
Although the United Kingdom voted itself out of the European Union in June of 2016, it’s still unclear what the effects of Brexit will be in Britain, the EU as well as the rest of the world. And that ...
If you’re not privy to the translation industry, translation memory and glossary are probably two terms that produce a look of confusion. For the unacquainted, these functions help to dramatically inc...
If you’re like many of our clients, you spend a lot of time and money developing high-quality English content. A lot of thought goes into the strategy, research, writing, design and production. Then y...
When a text gets translated from one language to the next, change is inevitable. Although human translators and the latest forms of machine translation always strive for perfect accuracy, it’s near im...
There’s a lot to learn in the translation industry. Keeping up with technological trends, regulations and industry standards can be a daunting task, especially if you’re new to the business. Add to th...
In this day and age, there aren’t many excuses for companies that don’t tap into foreign markets. The Internet has made global marketing more of a necessity than an option for business. With over 3 bi...
The month of November marks the beginning of the end of the calendar year. It is also in this month that we celebrate Thanksgiving in the United States. Thanksgiving is the first major national holida...
Russia has been in the news a lot recently. Reports of cyber-attacks, email hacks and surveillance have been flooding in as the 2016 U.S. presidential election comes to a close (you can read more abou...
A strong company cannot function without guidelines in place to prevent corruption. In particular, businesses around the globe need to be wary of bribery within an organization. According to The Organ...
Have the machines taken over yet? These days, sometimes it sure feels like it. And Google’s announcement last week that the company has devised a new machine translation method that’s purportedly almo...
Translators are connectors. They connect people, places and ideas with their ability to speak more than one language. They’re not only bi- or multi-lingual, but they’re also experts on the culture tha...
Silverware or cutlery? Highway or motorway? Sidewalk or pavement? If you’ve ever been an American in the United Kingdom or a Briton traveling in the United States, chances are you’ve had to learn each...
Canadian Hiring The debate over whether machines will replace humans in the translation industry has again come up in the news – this time the controversy surrounds a new vetting system for hiring fre...
What is an attestation or certification of translation and why do I need one? Attestations and certified document translations ensure the quality and cultural relevancy of the translated version of th...
As if Apple hasn’t already gotten enough slack recently for not incorporating a headphone jack into its newest iPhone, things got worse last week. Quite a bit worse. CBS News reported Friday that the ...
Join us in getting to know Len White of VIA's mid-market business localization team. Tell us about your background and what led you to becoming a localization account manager. Prior to VIA, I spent se...
This article was originally published in September 2016 and has been updated. The process of one person translating from one language into another, especially when it involves corporate and legal docu...
This article was originally published in September 2016 and has been updated. Technology continues to improve, making many tasks easier and more efficient. This is especially true in the world of tran...
It seems like every time I read the Wall Street Journal, I see those four dirty words that make global corporations cringe: Foreign Corrupt Practices Act (FCPA). According to The FCPA Blog, 87 compani...
By Maurizio Suppo, Principal Consultant, Qarad Good old days will be gone forever – the new EU MD and IVD regulations are coming fast! The European regulatory framework for MDs and IVDs has been drive...
Operating in 72 countries and territories with more than 20,000 locations, Starbucks has unprecedented global brand recognition. The white cup with the green logo and brown sleeve is on the forefront ...
As the international language of business, science, and academia, English is the most studied language in the world. There are 1.5 billion English language learners and 527 million native English spea...
According to Altman Weil's 2015 Chief Legal Officer Survey, law department leaders are taking an increasingly strategic approach to rein in costs. The 2015 survey found that 40% of law departments pla...
After recent updates, Google Translate now includes more than 100 languages, including Hawaiian and Kurdish. According to Google, this means the online translation tool, which is about to celebrate it...
Soccer is the world’s most widely watched and played sport. International soccer events like the FIFA World Cup draw millions of viewers and game attendees alike, all rooting for their national team. ...
One of the main chapters of the McDonalds success story is about convenient and consistent food – fast. When you order a Big Mac with fries, wherever you are in the world the taste should be the same....
No one wants to find themselves in an embarrassing or offensive situation in a foreign country because of innocent cultural mistakes. Often, this happens to tourists who are traveling abroad. But it c...
Localization is the process of adapting a product to the linguistic, cultural and technical requirements of a target market. It allows international users to interact with a product or marketing messa...



.png)
.png)















.png)
















.png)

.png)
.png)
.png)

.png)
.png)
.png)
.png)



.png)
.png)
.png)



.png)

.png)











.jpg)






.png)

.png)















_%20Can%20it%20Improve%20Clinical%20Trial%20Data_.png)








.png)






















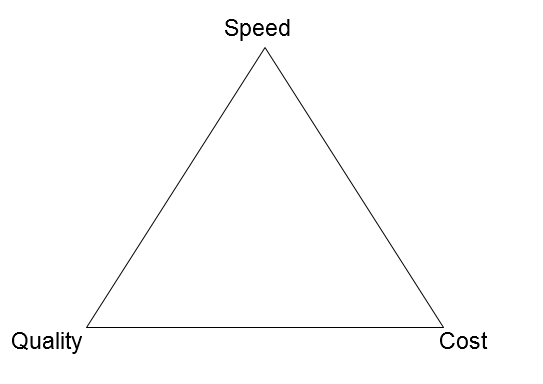















































































































.png)